Home Page
F.A.Qs
Statistical Charts
Past Contests
Scheduled Contests
Award Contest
| Online Judge | Problem Set | Authors | Online Contests | User | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Web Board Home Page F.A.Qs Statistical Charts | Current Contest Past Contests Scheduled Contests Award Contest | |||||||||
|
Language: DNA Sequence Alignment
Description Gnaileux Iew is attracted in Bioinformatics recently. He reads papers day and night and devotes all his mind in studying. Today he is going to review the basic problem in Bioinformatics: DNA sequence alignment. His purpose is to find a simple and effective algorithm that performs global alignment with two highly similar DNA sequences.
A DNA sequence is presented as a sequence of characters, which may be 'A', 'G', 'C' or 'T'. To align two DNA sequences, some gaps may be inserted to sequences so that two sequences have the same length. And then it is counted up for every pair of matched characters by a score matrix. Gnaileux Iew uses a minimal-score matrix hence the total score of alignment should be minimized. Following is the score matrix Gnaileux Iew uses: 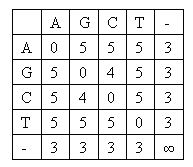 For example, an alignment for DNA sequences "AAGACG" and "CAGAGCTC" may be: -AAGA-C-G CA-GAGCTC The total score is 3+0+3+0+0+3+0+3+4=16. Gnaileux Iew is only interested in aligning highly similar sequences. Strictly speaking, |LCS(A,B)| * 2 / (|A |+ |B|) >= 90%, where A and B are the sequences to align, and LCS(A,B) is the longest common subsequence of A and B. Input Input contains multiple test cases. Each test case contains two lines, which are the two DNA sequences to align. DNA sequences contain only characters 'A', 'G', 'C' and 'T'. The length of each sequence is not greater than 50000.
You can assume that all the input cases are highly similar sequences. Output For each test case print the minimal total score of alignment in one line. Sample Input AGTGCTGAAAGTTGCGCCAGTGAC AGTGCTGAAGTTCGCCAGTTGACG CACAATTTTTCCCAGAGAGA CGAATTTTTCCCAGAGAGA Sample Output 12 7 Source POJ Monthly--2005.07.31, CHEN Shixi | |||||||||
[Submit] [Go Back] [Status] [Discuss]
All Rights Reserved 2003-2013 Ying Fuchen,Xu Pengcheng,Xie Di
Any problem, Please Contact Administrator